Life would be much easier and happier if we could travel back in time whenever we want and fix whatever mistakes we made. With time travel, you can figure out what caused a major outage three days ago (maybe go back in time and add more prints), or fix a tricky bug that led to data corruption! In this blog post, I'd like to show you how to make time travel easy and practical for distributed applications.

The key to practical time travel is transactions. To reproduce things that happened in the past, you have to faithfully reconstruct past program state like variables and files. In a typical distributed application where many threads or workers concurrently access shared state, this is nearly impossible: you have to record the precise order, potentially across machines, of each state access or update in disk or memory, and then replay operations in that order to faithfully reconstruct the program's state at a particular moment. However, if a program only uses transactions to access/update shared state, thanks to the ACID properties, we can faithfully reproduce a program's execution by simply recording the order of its transactions (helpfully done for us by the database) and replaying its transactions in that order.
Faithful replay also unlocks a powerful debugging feature called retroaction: re-execution of modified code over past events, for example, to test whether a bug fix actually fixes the issue. Let's say we have two concurrent requests R1 and R2 that both read some state and then try to update it. If the read and update aren't done in the same transaction, this could easily result in a race condition where R1 reads the state, R2 reads and updates the state, and then R1 updates the state without considering R2's update. Since this bug depends on a particular interleaving of requests, it's hard to test if a bug fix actually fixes the bug, or if your tests simply don't reproduce the race condition. However, we can leverage faithful replay to test this bug fix retroactively: we can restore the program state to a past point in time and re-execute our bug-fixed code over the original trace, which preserves the original order and concurrency of past state accesses and updates.
In order to achieve practical time travel through transactions, applications have to follow three rules:
- Store all shared state in data stores.
- Access/update shared state only through transactions.
- The output and state changes are deterministic.

To show these ideas can be practical, as part of my Ph.D. work at Stanford, I prototyped a time travel debugger called R3 (Record-Replay-Retroaction, pronounced "R-cubed") for transactional applications (source code, paper). R3 can faithfully replay past executions and retroactively execute modified code for applications written in Apiary (a research prototype of a transactional serverless platform). We diagram how R3 integrates with applications below. Its lightweight interceptor traces request and transaction information in production, and sends the trace to the data recorder to enable replay and retroaction in the testing runtime.
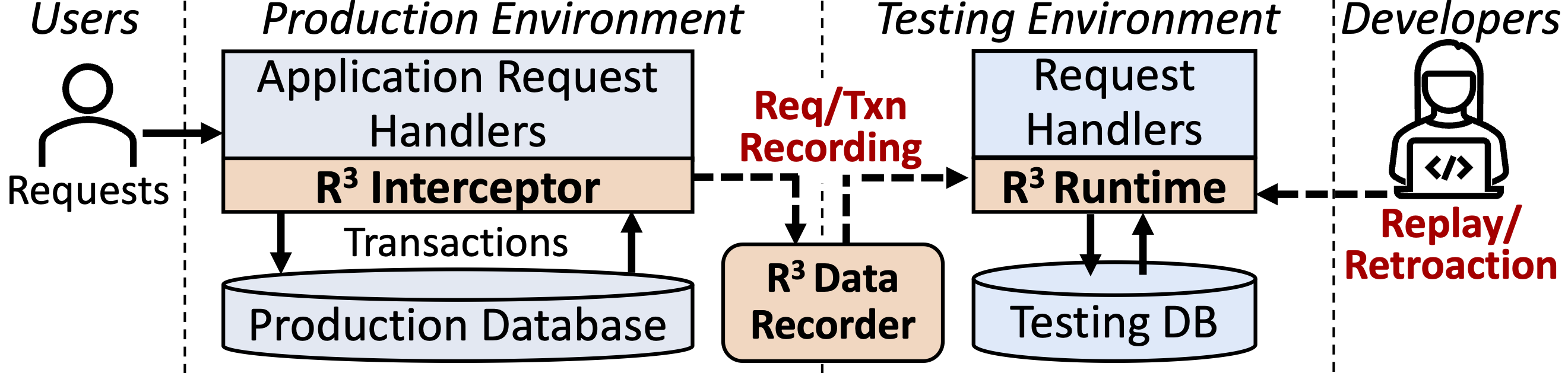
If R3 has collected a trace of an application, it can replay any events in the trace by restoring the database to the state immediately before the first replayed event (using database backups or Point-In-Time-Recovery), and coordinating transaction executions based on the recorded transaction log.
During replay, you can attach your favorite debugger such as gdb or jdb to view details of the executions.
You can also use R3 for retroaction by following the same step but with the modified code.
Now let's dive a bit deeper into the technical details. A big challenge in building R3 is supporting weaker isolation levels. If applications used (strictly) serializable isolation, we could simply replay transactions sequentially. However, for performance reasons, many applications and popular DBMSs use snapshot isolation (SI), where each transaction sees a snapshot of the database and can run concurrently with other transactions. We cannot simply replay such transactions sequentially because there may not exist a serial order. We also don't want to coordinate individual queries across concurrent transactions which is slow.
The trick is to reconstruct transaction snapshots. It turns out that we only need to capture per-transaction snapshot information during normal execution and reconstruct equivalent snapshots during replay. Our main idea here is to follow the original transaction start order to execute transactions, but after a transaction T completes we do not commit it right away. We instead commit transaction T right before the first transaction that has T in its snapshot. By explicitly controlling this, we can make sure that each transaction only sees data in its original snapshot. We formally proved the correctness of this algorithm in our paper.
Our idea applies to most data stores that support at least snapshot isolation. We prototyped with Postgres and found that R3 recording adds a small runtime performance overhead (up to 25% for point queries due to Postgres implementation, but negligible for more complex transactions like in TPC-C). Moreover, storage overhead is only 42 -- 100 bytes/request. This means if an application serves on average 1K requests/sec, R3 can store more than three months of traces in a single 1TB disk drive (which is fairly cheap according to Amazon) and allows developers to travel back to any time in that trace. With several optimizations, R3 can retroactively execute bug-fixed code within 0.11 -- 0.78x of the original time.
I had a lot of fun implementing R3. While developing it, I even used R3 to debug its own tricky concurrency bugs by looking into its transaction logs. Therefore, I believe transactions really make debugging easier (shameless plug: I wrote a CIDR'23 vision paper about this)! R3 fits into the broader theme of the DBOS project, where we've been researching how to leverage databases to build reliable and secure applications. If you are interested in R3 and want to learn more details about time-travel debugging, please check out our VLDB'23 paper and source code!
p.s., I will present R3 at VLDB'23 -- if you're attending the conference, welcome to join my talk and chat with me!
![]()
